Login required to access the wiki. Please register to create your login credentials We apologize for any inconvenience this may cause, but please note that this step is necessary to protect your privacy and ensure a safer browsing experience. Thank you for your cooperation. Documents available for download: GAMSO , GSBPM , GSIM |
16. The primary interest for the designer and the builder of a CSPA service is likely to be the physical specification of the information that will flow into and out of the service. The definition of the LIM and the specification of physical representations based on this logical model provide the way to translate agreed GSIM information objects into consistent, standards aligned, physical inputs and outputs for CSPA services.
17. For the Service Specification, we need LIM to describe information objects and the precise logical relationships between them in a manner which is consistent with GSIM. The primary interest for the builder of a CSPA service is likely to be the physical specification of the information that will flow into and out of the service. Depending on what information is being represented in practice, DDI and SDMX are currently expected to provide the primary basis for the physical representation of statistical information (e.g. data and metadata) in CSPA.
18. Logical modelling for CSPA will align to the maximum practical extent with the logical models associated with the candidate standards. In cases where complete alignment with existing standards is not practical, the usual decision will be for the LIM to align with one or other of the choices on a "best fit" basis. The following principles guide this decision.
- If there is a clear and unambiguous influence from an object in the logical model of another standard (such as DDI or SDMX) then:
- If that object has mandatory attributes, those should be mandatory in the LIM or the LIM must provide guidance to default that attribute once implemented.
- If that object has a relationship with another object that significantly affects its behaviour or use, that same relationship must exist in the LIM.
- Future known changes to that object should be accommodated for in the LIM.
- Try to maintain alignment with equivalent objects in the supporting physical standards, developers will need this alignment in place in order to implement. This will also maximize the ability for developers to reuse available toolkits.
- Only 'improve' objects from underlying physical standards once you have exhausted options to have those changes implemented in the physical standard; if the physical standard is changed, then reflect that change; if the physical standard isn't changed, explain the reason for the improvement.
- Consider emerging and alternative standards when trying to identify the need for new objects in the LIM – other standards may have already expended the effort required to address the use case.
- Consider using existing mapping work (for example between DDI and SDMX,) to help align these standards with the LIM.
- Make efforts to be aware of proposed and agreed future changes to key physical standards like DDI and SDMX.
The Logical Information Model
19. The LIM contains 9 packages which are based on the five GSIM Groups. The table below shows the relationship between the LIM packages and GSIM groups.
LIM Packages | GSIM Group |
Base | Base |
Business | Business |
Process |
|
Data and structural metadata | Structures |
Referential metadata |
|
Exchange | Exchange |
Questionnaire |
|
Concept | Concepts |
Variable |
|
20. The following sections detail those parts of the LIM that were developed in 2015. The focus of the text is to describe the use of the objects in a CSPA service and the differences from GSIM.
Base Package
21. Two new information objects were introduced in the LIM. These are Change Event and Agent In Role.
Change Event
22. The Change Event was introduced in order to have a general way to manage changes in the states of information objects.
23. Definition: A Change Event captures that a change has occurred. It identifies the information objects that have been affected, and the new information objects that have been created due to the change.
24. The Change Event has a date attribute which is used to convey the event time and a changeType attribute. In this release the attribute remains 'String' allowing for flexibleuse; however as more use cases are implemented, the expectation is that this will evolve into controlled vocabulary in order to accurately map to a recognized object lifecycle.
Agent In Role
25. Agent In Role was introduced in order to have a more flexible and extensible way of adding Roles to Agents without having to change existing information objects. The introduction of this object also provides a way to relate the Agent, Role and Administrative Details objects.
26. Definition: An Agent acting in a specific Role.
27. An Agent In Role may apply to either type of Agent - an Organization or Individual. The object is intended to reflect a single Agent acting in a single Role and as such is a very unambiguous representation. A common example would be to identify which Individuals or departments within an Organization provide administrative data. An Agent In Role is not in itself an Identifiable Artefact.

Figure 1: Base Group in LIM
28. Figure 1 shows the Base Group in LIM. Changes from GSIM v1.1 are described below:
Identifiable Artefact
29. An important decision was made that all attributes should be mandatory in Identifiable Artefact. The exception to this rule is Local ID. The consequence of this decision was a change in the cardinality of some attributes and the moving of some attributes to other Information objects.
After mapping to DDI, three new attributes were added (Local ID, Version Date and Version Rationale).
30. Two new usage relationships i.e. with the new information object Change Event.
31. The cardinality of the relationship to Administrative Details changed from 0 ... * to 0 ... 1. This both simplifies the model and provides focus for all non-mandatory attributes to be carried.
Agent
32. There has been one new usage association relationship introduced, from Agent In Role to Agent. Cardinality 0 ... * at Agent In Role and 1 at Agent. This replaces the relationship directly to Agent Role in GSIM v1.1
Process Package
33. There are a number of information objects defined in LIM to support the definition and execution of processes. These can be divided into two groups, those that are needed to design the process, and those that are used to capture the execution of a process.
Process Design
34. As part of the design of a service, the definition of the process that the service will perform is important. When the Process Steps are identified the next thing to do is to specify a Process Design for each step and identify how each Process Step will be performed. The result of the design, and the context and purpose for which the Process Steps will be used, are parts of the service specification that the service designer submits to the service builder.
35. Process Designs specify different types of inputs and outputs represented by the Process Input Specification and Process Output Specification. Examples of Process Inputs include data, metadata such as Statistical Classifications, Rules and Parameters. Process Outputs can be reports of various types (processing metrics), edited and/or new Data Sets and new or revised instances of metadata. The Process Design also consists of a Process Method which specifies the method to be used and is associated with a set of Rules to be applied.
36. The Process Control Design specifies the control logic, that is the sequencing and conditional flow logic within a Process Step/Service or between different Process Steps/Services. The flow describes what should happen next or what set of possible next steps can be performed after a specific Process Step.

Figure 2: Process Design
Process Execution
37. There are four information objects that are central to the implementation and execution of a Service. These are Process Step, Process Control, Process Input and Process Output.
38. While these are the four most important objects to clearly define the requirements of a service, there are other objects which also provide useful information for developing a service. These may include Process Step Instance (to capture the 'real-time' execution of the Process Step), and Process Design, Process Method and Rule (to further define the requirements that are to be implemented by the Process Step and service).

Figure 3: Process Execution
Moving from Design to Execution
39. Figure 4 shows the alignment between design-time and execution-time objects.
40. The most crucial aspect is that the execution-time Process Step encapsulates the whole Process Design, including the Process Method and Rules. The implementation of a Process Step will embed both the Process Method and Rule, where any configurable elements of the Rule will be supplied via the Process Input objects that are appropriate.
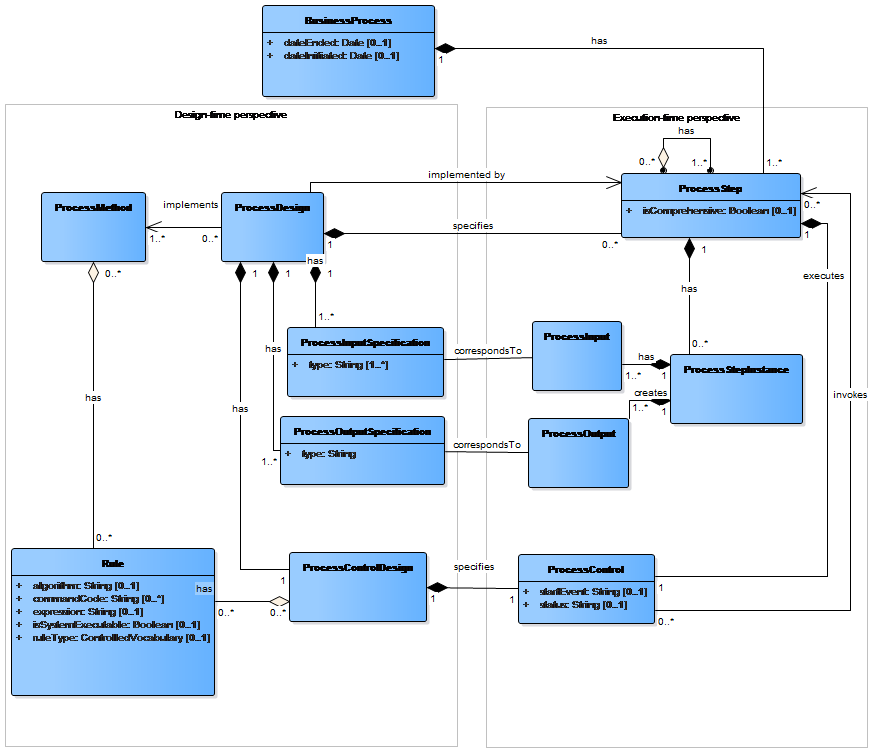
Figure 4: Alignment between design-time and execution-time
Process Step
41. GSIM Definition: A Process Step is a work package that performs a Business Process. A Process Step implements the Process Step Design specified in order to produce the outputs for which the Process Step was designed.
42. The Process Step outlines the required actions that will be executed by a Service. When designing and building the service, the information that was captured by the Process Step will specify what the Service is required to perform. This may also include information that was described in the Process Design, the Process Method, and the Rule.
43. Every time a Process Step is run, a Process Step Instance is created to capture the execution information, including the actual instances of the input information, and the resultant outputs.
Process Control
44. GSIM Definition: A set of decision points which determine the flow between the Process Steps used to perform a Business Process.
45. The Process Control defines the flow within the Process Steps, and also between different Process Steps. The Process Control can be implemented at different levels within a described process. It can describe the flow within a service, and also between different services.
46. Within a Service, a Process Control will be executed as part of a Process Step, and the Process Control will invoke the next Process Step.
47. Process Input and Process Output are used to identify the information and objects to be passed across the service boundary – that which is needed by the service to perform its function. There are three types of Process Input and three types of Process Output, which have been defined to specify the particular uses of information and objects in the service (input), and the different artefacts that are created as a result of the service (output). These objects were present in GSIM 1.0, but are not in the current version of GSIM (v1.1). They were reintroduced in LIM as they are very useful for Service Designers and Builders.
Process Input
48. GSIM Definition: Any instance of an information object which is supplied to a Process Step Instance at the time its execution is initiated.
49. Process Input might include information that is used as an input that will be transformed (e.g. a Data Set), information that is used to control specific parameters of the process (e.g. a Rule), and information that is used as reference to guide the process (e.g. a Code List).
50. There are three types of Process Input in LIM: Transformable Input, Process Support Input and Parameter Input.
Transformable Input
51. LIM Definition: A type of Process Input whose content goes into a Process Step and is changed in some way by the execution of that Process Step. Some or all of the content will be represented in the Transformed Output.
52. A Transformable Input is any object passed into a service that will be manipulated by the execution of the service. Typical Transformable Inputs are Data Sets and structural metadata (if changed by a process and needed to describe another output or as an object in their own right).
Process Support Input
53. LIM Definition: A form of Process Input that influences the work performed by the Process Step, and therefore influences its outcome.
54. A Process Support Input is a resource that is referenced or used to guide the service in completing its execution. This could include look up guides, background data, or classifiers used as part of the service.
55. Some examples of a Process Support Input could include:
- A Code List which will be used to check whether the Codes recorded in one dimension of a Data Set are valid, or
- An auxiliary Data Set which will influence imputation for, or editing of, a primary Data Set which has been submitted to the Process Step as the Transformable Input.
Parameter Input
56. LIM Definition: Inputs used to specify which configuration should be used for a specific Process Step, which has been designed to be configurable.
57. Parameter Inputs may be provided where Rules and/or Business Service interfaces associated with a particular Process Step have been designed to be configurable based on inputs passed in to the Service.
58. Some examples of a Parameter Input could include:
- Threshold values
- Ranges (such as upperLimit and lowerLimit)
Process Output
59. GSIM Definition: Any instance of an information object which is produced by a Process Step as a result of its execution.
60. Process Output might include information that has been transformed or created as part of the service execution, or an operational or methodological measure captured during the execution.
61. There are three types of Process Output in LIM: Transformed Output, Process Execution Log and Process Metric.
Transformed Output
62. LIM Definition: A Process Output (a result) which provides the "reason for existence" for the Process Step.
63. A Transformed Output is the product of the actions that were executed by the Service. Typically, a Transformed Output could be considered the updated ("value added") version of one or more Transformable Inputs supplied to the Service.
64. For example, a Process Step with the Business Function of imputing missing values is likely to result, as its Transformed Output, in a Data Set where values that were missing previously have been imputed.
Process Execution Log
65. LIM Definition: The Process Execution Log captures the output of a Process Step which is not directly related to the Transformed Output it produced. It may include data that was recorded during the real time execution of the Process Step.
66. A Process Execution Log captures the information that is collected as part of a service for operational purposes. A typical example is to capture error conditions, or the time it took to complete the service.
67. Every time a Process Step/Service is run, a Process Step Instance is created to capture the "real-time" execution information of the Process Step, including the actual instances of inputted information, and the resultant outputs.
Process Metric
68. LIM Definition: A Process Output whose purpose is to measure and report quality or methodological aspects of the Process Step performed during execution.
69. A Process Metric records the quality or methodological measurements about the execution of a service. One purpose for a Process Metric may be to provide a quality measure related to the Transformed Output.
70. For example, statistical quality measures generated as part of a Service may include a measure of how many records were imputed, and a measure of how much difference, statistically, the imputed values make to the Data Set overall.
Data & structural metadata Package
71. Almost all services require Data Sets as a Process Input in order to do carry out meaningful processing. The LIM enables you to describe a Data Set and its internal structure in a standard way so that it can be processed by CSPA services.
72. A Data Set is a collection of Data Points that conform to a known structure described by a Data Structure and its components. A Data Set may be either a Unit Data Set or a Dimensional Data Set.
73. Unit data and dimensional data are perspectives on data. Although not typically the case, the same set of data could be described both ways. Sometimes what is considered dimensional data by one organization (for example, a national statistical office) might be considered unit data by another (for example, Eurostat where the unit is the member state). A particular collection of data need not be considered to be intrinsically one or the other. This matter of perspective is conceptual. In GSIM, the distinction is that a Unit Data Set contains data about Units and a Dimensional Data Set contains data about either Units or Populations.

Figure 5: Unit Data Sets
74. A typical example of a Unit Data Set is census data. The model for Unit Data Set is shown in Figure 5.
75. A typical example of a Dimensional Data Set is an aggregated data cube, where the microdata have been summed. The model for Dimensional Data Set is shown in Figure 6.

Figure 6: Dimensional Data Sets
76.One new object – Component Relationship -was added to LIM in the Data and Structural Metadata package.
77. This reflects that there could be a structure within the Logical Record, for example several fields can together represent a structured field (e.g. an address), or the record can be structured as in the case of an XML file conformant to a schema.
78. Changes from GSIM v1.1 are described below:
Data Structure
79. The composition relationship between Data Structure Component and Data Structure was removed for modelling purposes (coherence with the inheritance mechanism between the Components and Data Structure Component and its related cardinalities).
Attribute Component
80.A number of optional attributes were added to this object:
- The assignmentStatus attribute was added to indicate if an attribute defined in a Data Structure is optional or mandatory in a Data Set.
- An attachmentLevel attribute indicates the level to which an attribute is attached: it could be an observation, a dataset or series.
Identifier Component
81.A number of optional attributes were added to this object
- The isUnique attribute identifies if an Identifier Component uniquely identifies records in the Data Sets the corresponding Data Structure describes.
- The isComposite attribute specifies at the level of the Data Structure Components if the component alone is able to uniquely identify a record in the corresponding Data Sets.
- The role attribute is inspired from SDMX dimension roles, an initial controlled vocabulary proposed for this attributes contains the following 5 values: entity (e.g. personal identification number), identity (e.g. arbitrary number), count, time or geography.
82. Together the isUnique and isComposite attributes allow knowing if and how records can be uniquely identified in Data Sets corresponding to the Data Structure. This corresponds to the identification of unique keys and composite keys in ordinary databases. In LIM the fact that a key is composite can be derived by the number of Identifier Components, but it is believed it can be relevant to express at the level of an Identifier Component that it cannot identify a record by itself. The isUnique attribute adds information that cannot be derived from other elements.
83.The role attribute is used to characterize what is represented by an Identifier Component. For instance embedding in the LIM the identification of time and geography dimensions may allow for automated treatment of time/geography information based directly on the semantics of the model. This is believe to generate opportunities concerning automated treatment of LIM-compliant data independently of the specific content hosted by the model.
Dimensional Data Set
84.A number of optional attributes were added to this object:
- The action attribute defines the action to be taken by the recipient system (replace, append, delete, information).
- The dataExtractionDate attribute describes the date and time that the data are extracted from a data source.
- The reportingBegin attribute describes the start date/time frame for the Data Set
- The reportingEnd attribute describes the end date/time frame for the Data Set
85. A Logical Information Model should stop at the logical level. When you translate the logical Data Set object from LIM into DDI or SDMX you are able to define more concrete physical aspects. This is conveyed in the Service Implementation document, not in the LIM.
Concepts Package
Statistical Classification
86. The Generic Statistical Information Model (GSIM): Statistical Classifications Model v1.1, defines the key concepts that are relevant to structuring Statistical Classification metadata, and provides the conceptual framework for the development of a Statistical Classification management system. It is aimed at classification experts.
87. LIM is aimed at service developers. In order to produce CSPA Statistical Classification services, seemingly redundant attributes have been removed i.e. replaced by relationships, and the number of attributes has been reduced to cover only those used by more than 60% of those organisations that have documented their use of GSIM Statistical Classifications in their GSIM Case studies (August 2015).
88. In LIM all information objects must use the attributes of the Identifiable Artefact and can use attributes from Administrative Details as needed. Changes in naming, cardinality and value type (e.g. text in GSIM is multilingual text in LIM) of a few attributes from GSIM Statistical Classification Model v1.1 have been made in LIM for greater consistency across all the information objects used and/or produced by CSPA services. For more details see comments per attribute below.
Statistical Classification
Name | Description | Cardinality | Value domain | Comment |
description | The description provides details of the Statistical Classification, the background for its creation, the classification variable and objects/units classified, classification rules etc. | 0...1 | Multilingual text | Introduction and Description in GSIM are combined |
validFrom | Date on which the Statistical Classification was released. | 0....1 | Date | Release Date in GSIM |
validTo | Date on which the Statistical Classification was superseded by a successor version or otherwise ceased to be valid. | 0....1 | Date | Termination Date in GSIM |
Level
Name | Description | Cardinality | Value domain | Comment |
numberOf Items | The number of items (Categories) at the Level. | 0...1 | Integer | Text in GSIM |

Figure 7: Statistical Classification
Code List
89. LIM for Code Lists started before LIM for Statistical Classifications in order to test out methods of working and the time needed to reach agreement for a run-time service. It may be necessary to expand the following minimal list of attributes and relationships when designing a Code List management system.

Figure 8: Code List
90. Note that in LIM a new relationship was introduced to the Node Set object allowing a Node Set to be 'basedOn' a Concept. This introduces the possibility of building a concept-based model for representing Code Lists, and is expected to further support the use of the LIM in future work regarding semantic technology.
Code Item
91. The Code Item has inherited a relationship to Concept via the Node object. As above (for Code List), this introduction allows a concept-based model for Code Lists and codes; it additionally supports any future use of concept mapping across Data Sets via the codes represented in them. For the purposes of data integration, a semantic graph across concepts can now be theoretically navigated to inter-relate observations contained in different Data Sets.

Figure 9: Code Item