Login required to access the wiki. Please register to create your login credentials We apologize for any inconvenience this may cause, but please note that this step is necessary to protect your privacy and ensure a safer browsing experience. Thank you for your cooperation. Documents available for download: GAMSO , GSBPM , GSIM |
I. CSPA Implementation Guidance
1. Effectively implementing CSPA compliant shared statistical services requires that the implementation management and support aspects (international and local) needed to implement them efficiently and reliably are in place and well understood. Following is the set of CSPA implementation guidance to support Statistical Organizations.
II. Protocols for invoking service endpoints
2. The protocols for invoking service endpoints in a Request/Response pattern recommended by CSPA are:
- SOAP Web Services: you can build services according to WS-I (https://en.wikipedia.org/wiki/WS-I_Basic_Profile) when the objects are more sensitive in nature and hence the transport is more likely to need encryption and the session needs authentication. Also, consider this standard when the actions move beyond read and those objects are created, deleted or modified during the interaction. Although this could increase development times, it makes for a more reliable and trustworthy service from the perspective of the implementer and as such, will be less likely to result in the need to further wrap the service to meet local security architecture needs.
- REST Web Services: you can build services according to the REST architecture (https://en.wikipedia.org/wiki/Representational_state_transfer) when the objects are largely accessed by external and wide audiences, those objects are not sensitive and the action is Read-Only. This improves portability, increases re-use and simplifies implementation and consumption.
3. WS-I natively expose the service documentation through WSDL. Such a standard doesn’t exist for REST services but we found that tools like Swagger (http://swagger.io/) or RAML (http://raml.org/) provide a good documentation solution.
4. The following solutions are recommended to implement Asynchronous Queuing / Event-driven Messaging patterns:
- Message queue / message broker: services communicate asynchronously via messages sent to or read in queues (or topic).
- File-based invocation: the service is "invoked" when a file is placed at a known location which results in an OS-level trigger to the service; alternatively, the service can poll the location for arrival of "message" files and treat them as service invocations
5. In some cases, a service can be invoked by specifying a command line to be executed on operating system runtime accessible by the platform.
6. In some instances, existing tools support database access. If the database is involved in transfer (and not merely as a local state storage for the service), we recommend that the database access be mediated through the http protocol.
7. In general, the use of an "out of band" data transfer mechanism should be avoided wherever possible and used only in circumstances involving the need to transfer large volumes of data. Its addition adds increased coupling between the architecture and services, so its use must be managed carefully.
III. Protocols for passing data by reference
8. CSPA provides the following guidance for service input dataset retrieval protocols:
Recommended protocols:
- Simple http file transfer from data source to the service logic (without additional protocols such as REST)
Acceptable protocols:
- ftp file transfer from the data source to the service logic
- Use of network file system services (such as SMB, NFS) with appropriate file reference
Not Recommended:
- Database retrieval using queries
IV. Which Pattern do I use?
9. When building CSPA-services and when building an environment to integrate CSPA-services, architectural patterns are used to design these solutions. Architectural design patterns are used to increase the “plugability” of services and to ensure that new designs for services and environments make use of both good and bad experiences within the statistical community. The patterns in the CSPA-architecture is a subset of the SOA-architectural patterns and as the statistical community builds up experience with the CSPA-standard, the experiences will be transformed into more and more precise guidance.
10. When a statistical organization starts building and integrating CSPA-services, it is common to focus more on the CSPA-services and less on how these are integrated. For each consumer of the CSPA-services, specific logic is used to make use of multiple CSPA-services. This is sometimes referred to as "glue code" and serves as a quick way to get started. Some integration solutions don’t make use of code but rather a higher level of configuration or similar but the outcome is the same.

Figure 1: “Glue code”
11. As more and more consumers are reusing the same services, the "glue code" requires more and more maintenance. Making changes to the logic of how these services are used becomes difficult since the integration logic is decentralized.
12. Since this pattern isn’t sustainable for an organization which wants to increase its usage of the CSPA-architecture, a more thought through pattern should be used for integrating CSPA-services.
The support the integration between services is a more sustainable way. A suggested approach is to make use of a broker which handles the communication. Brokers support different communication patterns and can be used in a number of ways depending on what the situation calls for.
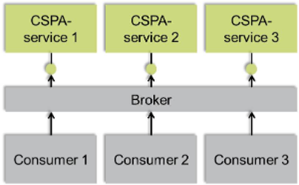
Figure 2: Broker communication
13. A single type of broker or communication pattern will not be the best match for all statistical organizations and will likely not even be the best match for all parts in the production process. Different organizations have different preconditions and there could be numerous of reasons why a specific solution is selected.
14. One type of broker that has been used by several statistical organizations for integrating services is to a broker with an orchestration capability. These brokers allow the consumer to define how the workflow between the services should look or could allow for a more centralized control over how the integration between the services should operate for all consumers. There are several brokers with orchestration capabilities and these are sometimes referred to as Business Process Management Systems (BPMS) or workflow engines.
15. The benefit from investing in a BPMS is that this allows for a more sustainable approach of adopting the CSPA-architecture since the integration logic is more centralized than in a situation where “glue code” is used.
16. Experiences in using this pattern, outside the statistical community and also in some statistical organizations, shows that this could be seen as a battle tested approach for integrating services but it also comes with some downsides.
V. Functional Services vs Entity services
17. A functional service implements a business function as a service (verb), while an entity service implements a service for interacting with business artefacts (noun). Examples of these can be a service that executes a particular statistical method, and a service that looks up a classification.
18. In a complete statistical system, both would be needed as they serve different purposes. A functional service implements a particular business function, and an entity service will provide you with the business artefacts as a service, which will be used either as a stand-alone service, or in orchestration with the functional services.
19. An entity service will likely only be of concrete use as a CSPA-service in the context of a non-event based SOA, as entities are attached and addressed in a different way in an event based SOA, and therefore will be standardized and attached to the communication framework of an organization's environment. An entity service will still be useful as a standardized way of retrieving different types of information artefacts from systems that previously required specialized access, and as part of a move towards a service oriented architecture.
20. A CSPA service can also be a combination of both of these types of services. An example could be a CSPA service that supports a specific GSBPM process (3.1 Build collection instrument) that provides a GSIM output (a questionnaire).
VI. Guidelines for the creation of content for the Technical /Supporting Services Catalogue
21. The current CSPA Technical/Supporting Services Catalogue is Github.com, an example can be viewed at: https://github.com/edwindj/cspa_rest/tree/ea9d59b5afbb4764cca6b34f5d3120f3cf7c16e6.
22. A Technical Repository contains one or more CSPA Service Implementations for exactly one CSPA Service. For example: a .NET implementation and a Java implementation.
23. The Technical repository contains the following general artifacts:
- A Readme, like a README.md file on Github. For each of the implementations in the repository this Readme contains a reference to Implementation Description in the Global Service Catalogue. Also, it explains how to use the repository.
- A facility for issue management;
- A Deployment Manual, describing how to pick and deploy one of the implementations of the CSPA Service. This manual contains:
- A description of the deployment “happy flow”, which is the default environment of the service to run on. For example: a VirtualBox 4.3.18 or higher environment where each virtual machine has Internet access and gets a static IP address.
- Any number of appendices describing “alternative flows” for other implementation environments. For example: a Windows 8 environment with SQL Server 2008, Active Directory and without an Internet Connection. Users of the service may add additional Appendices to this manual as they implement the service on their specific environments.
24. It contains, for each implementation:
- The software required to deploy the implementation;
- The legal license information applicable to the implementation (like a LICENSE file on Github);
- Testware to verify whether a deployed service is actually working as it should.
25. It contains, for each open source implementation:
- The source code.
- A Development Manual, describing how to contribute to the repository, like a CONTRIBUTING.md file on Github (https://github.com/blog/1184-contributing-guidelines). This manual contains:
- A description of (an example) development environment that should be used to develop the service further. For example: Microsoft Visual Studio 2012 or higher for a .NET-based implementation;
- Specific source code conventions, if applicable;
- Directions on how to organize the source code, file names, etcetera;
- Directions on branching, the logical unit of check-ins and how to document check-ins.