Explanation of the diagram
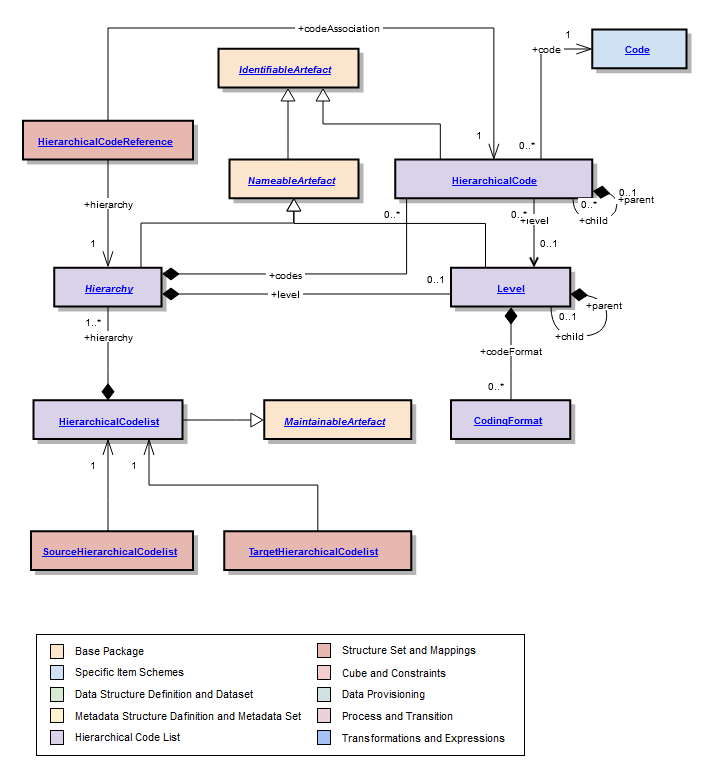
Codelist described in the section on structural definitions supports a simple hierarchy of Codes, and restricts any child Code to having just one parent Code. Whilst this structure is useful for supporting the needs of the DataStructureDefinition and the MetadataStructureDefinition, it may not sufficient for supporting the more complex associations between codes that are often found in coding schemes such as a classification scheme. Often, the Codelist used in a DataStructureDefinition is derived from a more complex coding scheme. Access to such a coding scheme can aid applications, such as OLAP applications or data visualisation systems, to give more views of the data than would be possible with the simple Codelist used in the DataStructureDefinition.
Note that a hierarchical code list is not necessarily a balanced tree. A balanced tree is where levels are pre-defined and fixed, (i.e. a level always has the same set of codes, and any code has a fixed parent and child relationship to other codes). A statistical classification is an example of a balanced tree, and the support for a balanced hierarchy is a sub set, and special case, of the hierarchical code list.
The principal features of the HierarchicalCodelist are:
- A child code can have more than one parent.
- There can be more than one code that has no parent (i.e. more than one “root node”).
- There may be many hierarchies (or “views”) defined, in terms of the associations between the codes. Each hierarchy serves a particular purpose in the reporting, analysis, or dissemination of data.
- The levels in a hierarchy can be explicitly defined or they can be implicit: (i.e. they exist only as parent/child relationships in the coding structure).
The basic principles of the HierarchicalCodelist are:
- The HierarchicalCodelist is a specification of the Codes comprising the scheme and the specification of the structure of the Codes in the scheme in terms of one or more Hierarchy.
- The Codes in the HierarchicalCodelist are not themselves a part of the scheme, rather they are references to Codes in one or more external Codelists.
- Any individual Code may participate in many Hierarchys, in order to give structure to the HierarchicalCodelist.
- The Hierarchy of Codes is specified in HierarchicalCode. This references the Code and its immediate child HierarchicalCodes.
- A Hierarchy can have formal levels (hasFormalLevels=”true”). However, even if hasFormalLevels=”false” the Hierarchy can still have one or more Levels associated in order to document information about the HierarchicalCodes.
If hasFormalLevels= “false” the Hierarchy is “value based” comprising a hierarchy of codes with no formal Levels. If hasFormalLevels=”true” then the hierarchy is “level based” where each Level is a formal Level in the HierarchicalCodeList, such as those present in statistical classifications. In a “level based” hierarchy each HierarchicalCode is linked to the Level in which it resides (which must be in the same Hierarchy as the HierarchicalCode). It is expected that all HierarchicalCodes at the same hierarchic level defined by the +parent/+child association will be linked to the same Level. Note that the +level association need only be specified if the HierarchicalCode is at a different hierarchical level ((implied by the HierarchicalCode parent/child association) than the actual Level in the level hierarchy (implied by the Level parent/child association).
[Note that organisations wishing to be compliant with accepted models for statistical classifications should ensure that the Id is the number associated with the Level, where Levels are numbered consecutively starting with level 1 at the highest Level].
The Level may have CodingFormat information defined (e.g. coding type at that level).
Some statistical systems create views of data based on a “cube” structure. In essence, a cube is an n-dimensional object where the value of each dimension can be derived from a hierarchical code list. The utility of such cube systems is that it is possible to “roll up” or “drill down” each of the hierarchy levels for each of the dimensions to specify the level of granularity required to give a “view” of the data – some dimensions may be rolled up, others may be drilled down. Such systems give a dynamic view of the data, with aggregated values for rolled up dimension positions. For example, the individual countries may be rolled up into an economic region such as the EU, or a geographical region such as Europe, whilst another dimension, such as “type of road” may be drilled down to its lower level. The resulting measure (such as “number of accidents”) would then be an aggregation of the value for each individual country for the specific type of road.
Such cube systems rely, not on simple code lists, but on hierarchical code sets. Data reported using a Data Structure Definition structure (where each dimension value, if coded, is taken from a flat code list) can be described by a cube definition and can be processed by cube aware systems. The SDMX-IM supports the definition of such cubes in the following way:
- The HierachicalCodelist defines the (often complex) hierarchies of codes
- If required, the StructureSet can:
- o group DataStructureDefinition that describe the cube,
- o provide a mapping mechanism between the codes in the flat code lists used by the DataStructureDefinition and a HierarchicalCodelist where the HierarchicalCodelist uses code lists that are not used in the DataStructureDefinition.