Login required to access some wiki spaces. Please register to create your login credentials
|
50. CSDA is (loosely) based on TOGAF. According to TOGAF 9 definitions[1], a capability is "an ability that an organization, person, or system possesses. Capabilities are typically expressed in general and high-level terms and typically require a combination of organization, people, processes, and technology to achieve. For example, marketing, customer contact, or outbound telemarketing".
51. This aligns with the definition provided by CSPA: "Capabilities provide the statistical organisation with the ability to undertake a specific activity. A capability is only achieved through the integration of all relevant capability elements (e.g. methods, processes, standards and frameworks, IT systems and people skills)".
52. In CSDA, capabilities are expressed at the conceptual level, which means they are defined in terms of “what” and “why”, rather than “how”, “who” and “where”. In scope, the CSDA Capabilities are restricted to activities regarding the management and use of statistical data and metadata.
53. In the following sections, the set of capabilities selected for CSDA is presented.
A. Capability Definition Principles
54. The principles below are designed to direct the effort of defining a proper set of capabilities, specifically for CSDA, but potentially also in other areas. Their purpose is to help in answering the question “How does one properly define a capability?”. These principles are an extension of the description of what capabilities are in other standards such as TOGAF. This set of principles is based on earlier work by Stats New Zealand.
Table 2: Capability Definition Principles
Statement | Description | Rationale | Consequences |
Capabilities are abstractions of the organization. They are the “what?” and “why?” not the “how?”, “who?”, or “where” | Capabilities are abstractions of "what" an organization does. Capabilities are conceptual. They are completely separated from "how" the organization chooses to implement them. | Business capabilities are about defining what needs to be delivered and why it needs to be delivered but does not define the how it will be delivered. | A clear understanding is required of what the abilities are, as opposed to how they are implemented or executed. The “How” is postponed to later stages in the development process. |
Capabilities capture the business’ interests and will not be decomposed beyond the level at which they are useful | Capabilities are expected to be defined to a level at which it is useful to the stakeholders, i.e. strategic level management. Top level capabilities may be decomposed into more detailed lower level capabilities, but decomposition will stop at the level where further decomposition brings no clear advantage. | An appropriate level of detail is required for a good (enough) understanding. Further detail does not help at the strategic level and should be postponed until real development (i.e. design & build). At that stage, other architectural constructs are needed. | The set of capabilities will be restricted to a reasonable number of capabilities. Capability definitions and descriptions need to be concise, i.e. brief but comprehensive. |
Capabilities represent stable, self-contained business functions | Both the function and the capability must be enduring and stable unlike the processes, strategy & initiatives which can change frequently. | Capabilities should be self-contained pieces of a business that potentially could be sourced from another business unit, another agency, or an external provider. If it cannot be logically separated and shifted it might be too detailed. | Any capability should be essential and inherent to the business, now and in the foreseeable future |
The set of capabilities should (completely) cover the space of interest | The set of capabilities should be exhaustive and should include everything the organization needs to be able to do to be successful. | Leaving gaps means running the risk of oversight, i.e. missing potentially important facets in strategic decision making. Including capabilities outside the scope directs focus away from the relevant area. | A clear scope of the “space of interest” is required. |
Capabilities should be non-overlapping | No two capabilities should cover the same abilities. | Overlapping implies redundancy and potential conflicts in implementation, which also hampers strategic decision-making. | Higher level capabilities cannot share lower level capabilities. |
B. Overview
55. The set of capabilities selected for CSDA represents those capabilities that an organization would need to be able to fully live up to the Key Principles presented in chapter VI. These are the capabilities that collectively enable the organization to properly treat its data as an asset.
56. A subset of these capabilities is used to formulate and implement the policies that the organization chooses for its internal operations. This subset is called “cross-cutting capabilities”, because the policies direct and manage how all (information related) work is done. The Cross-cutting capabilities represent abilities that GAMSO calls “Corporate Support Activities”, and GSBPM calls “Overarching processes”.
57. The remaining capabilities are collectively called “Core capabilities” because these are the capabilities that the organization needs to execute its core business, the production of statistics. These capabilities therefore align with phases of GSBPM.
58. Each capability is further decomposed into lower level capabilities.
59. There are 5 (top level) Core Capabilities:
- Data Design & Description
- Information Logistics
- Information Sharing
- Data Transformation
- Data integration
60. Data Design & Description, that is, the creation of metadata, both prescribing and describing, is separated out as a capability in its own right, because it is clear that data cannot be used and shared unless it is properly described.
61. Information Logistics and Sharing always work together. Information Logistics deals with all the nitty-gritty of storing and moving data around. Information Sharing is about the more business oriented activities of sharing data. This has two sides to it: the “giving” and the “taking”, i.e. making data and metadata available versus the searching, finding and retrieving.
62. Data Transformation and Data Integration is what makes up the essence of statistical production: the refinement, linking and aggregation of data into statistical output products.
63. There are 4 (top level) Cross-cutting capabilities:
- Information Governance
- Security & Information Assurance
- Provenance & Lineage
- Knowledge Management
64. Information Governance comprises all the abilities that have to do with defining and enforcing policies around proper governance of data and metadata.
65. Security and Information Assurance deals with defining and enforcing policies that ensure appropriate protection of data and metadata, against various threats and risks.
66. Provenance and Lineage is the ability to maintain and provide information about the origin and derivation of data and metadata.
67. Knowledge Management, in this version, is positioned as a separate (cross-cutting) capability, because it is a rather new domain in the world of official statistics that is still somewhat vague. But the expectation is that this will become better understood and integrated with the rest in future.
68. The next figure shows the 9 top level capabilities, each with its second level components. All of these capabilities are further described in the following sections.

Figure 3: Capability Overview
C. Data Design & Description
Summary
69. The ability to design and describe, prescribe, and assess data and the structures that organize them.
70. This includes:
- Enabling consumers of information assets to understand their contents regardless of their technical implementation.
- Maintaining mappings between data assets and relevant metadata structures to support other capabilities in the architecture, e.g. data search, exploration and analysis.
- Assessing quality of data assets in terms of their data and associated metadata.
- Providing data models at multiple levels of abstraction using standards, when possible, to support both metadata-driven processes and communication.
Lower Level Capabilities
71. The Lower Level Capabilities for the Data Description & Organization capability are:
- Information Set Design
Create conceptual, logical and physical information set designs, i.e. designs of organized collections of statistical content.
Specialisations are:- Dataset Design
- Metadata Set Design
- Data Profiling
Assess and summarize datasets to determine data quality levels, accuracy and descriptive metadata completeness. - Data Abstraction
Describe data and its structures in such a way that information consumers can understand the data contents without any detailed knowledge of the underlying physical and technical implementation. - Data Modeling and Structuring
Represent datasets in terms of information objects, relationships and constraints to formally describe information contents and their organizations. - Metadata and Schema Linkage
Maintain links between datasets, schemas, and other types of metadata to describe (and prescribe) information contents and support metadata-driven data processing.

Figure 4: Data Design & Description
Description
72. Data Design and Description is a capability that structures, organizes, abstracts and describes information (specifically: data) assets so that they can be made available, and findable, to other capabilities in the architecture.
73. It includes both the purposeful design of datasets, based on known information requirements, and the reverse-engineering of information assets. In both cases it entails formally representing data in a precise form in data models at various levels of abstraction. Data models are not only diagrams but also any associated documentation that helps to understand information contents and drive data profiling activities.
74. Models at higher levels of abstraction, e.g. conceptual, are usually in business language to enable consumers to understand the information contents regardless of their implementation. They describe business objects and their relationships. An example of a data model at the conceptual level is the Generic Statistical Information Model (GSIM), which in fact is a meta-model. Models at lower levels of abstraction, e.g. physical, tend to be implementation-dependent and machine-actionable, e.g. database schemas. They describe how data points are organized into a variety of structures, e.g. records, tables, trees, graphs, etc. Examples of such models are the Data Documentation Initiative (DDI) and the Statistical Data and Metadata Exchange (SDMX).
75. This capability also maintains the mappings between information assets and associated structures, i.e. metadata and schemas, including data models. The structures associated with the information assets could be prescriptive or descriptive. Prescriptive (or normative) metadata establishes what “must be” via rules that need to be applied to achieve full compliance. In some cases the rules are fully enforced, e.g. integrity constraints (rules) as defined in database schemas, where a data instance cannot even be loaded unless it satisfies all constraints in the schema. In other cases there is a relaxation of those rules, and the "must be" becomes a "should be" with multiple levels of compliance. Examples of those are business rules establishing the metadata objects required to ensure the best possible data quality to data consumers, but where having incomplete metadata is still acceptable. In contrast, descriptive (or informative) metadata provides information about “what is”, i.e. it describes a single data instance without any general rule. Examples of those are the record layouts describing CSV files.
76. Metadata has three important aspects: semantic consistency, conformance to standards and actionability.
- Semantic consistency means that metadata is precisely defined according to a well-known modelling framework, and that coherent naming rules are established and applied throughout the organisation. This could require specific skills and organisational measures. This also includes building ontologies and dictionaries and semantic analysis of data to ensure semantic consistency.
- Conformance to standards is a good way to achieve semantic consistency, since standards usually undergo collaborative production processes that confer them a high quality level. It is also essential to interoperability between organisations, notably at an international level. It may be useful for statistical organisations to participate in the governance of the standards that they use.
- Actionability means that metadata is not only documentation (i.e. a passive role), it is also used to drive the manual and automated parts of the statistical production process (the active role). This active role can also be seen in driving (enforcing) conformance to standards and semantic consistency. For metadata being able to take this active role, it usually means that the metadata is stored in specific machine-actionable formats, which requires particular expertise.
D. Information Logistics
Summary
77. The ability to make and keep information available to consumption points and manage information supply chains between providers and consumers.
78. This includes:
- Finding and characterizing relevant information sources for statistical production purposes.
- Connecting to information sources through a variety of channels (for example API, web questionnaires, administrative archives, statistical registers, streaming data, etc.).
- Managing the relationship with information providers (for example respondent management and service level agreements for administrative data sources).
- Ensuring information provisioning by maintaining channel operations.
- Enabling information exchange between applications and consumers.
- Manage information at-rest and in-motion, both physically and virtually.
Lower Level Capabilities
79. The lower level capabilities for the Information Logistics capability are:
- Needs Discovery & Profiling
Identify, assess and summarize information needs at different granularities and within a variety of scopes, both internally and externally. - Source Discovery & Profiling
Find existing sources (enterprise data hubs, admin data registers, operational data stores, social networks, etc.) that may hold information of interest and characterize the data and metadata they contain. Sources may be found outside, but also inside the own organization, such as other statistical processes, internal (backbone) registers, etc. - Exchange
Exchange statistical information between parties, both external and internal to the own organization.- Channel Management
Create, maintain and withdraw information (exchange) channels, including their descriptive and/or actionable metadata. - Channel Configuration & Operation
Configure information (exchange) channels for specific types of (data and metadata) traffic and maintain channel operation in accordance with service level agreements and other types of contracts. - Relationship Management
Manage relationships with information exchange partners, both internal and external, by establishing and monitoring service level agreements and other types of contracts.
Specialisations are:- Information Provider Management
- Information Consumer Management
- Data Flow Management
Manage data in-motion as streams and setup and maintain data pipelines for real-time usage.
- Channel Management
- Persistence
Keep information available in the selected physical or virtual location (i.e. at-rest) over time.
Specialisations are:- Data Persistence
- Metadata Persistence
- Data Virtualization
Dynamically create and maintain virtual (i.e. not physically stored) representations of data to simplify delivery, access and persistence and minimize data movement.

Figure 5: Information Logistics
Description
80. Information Logistics deals with the nitty-gritty of accessing, storing and moving data and metadata. This ability works closely together with Information Sharing.
81. Managing information storage (persistence) and exchange is the core of Information Logistics. This includes establishing and securing information provision agreements with relevant providers and consumers, both internal and external to the organization. It also includes ensuring the channels can operate with all necessary data pipelines and technologies.
82. Data pipelines consists of coherent and integrated mechanisms to manage data flows and data in motion in general, including event management, messaging, connections to persistent stores, workflow management and serialization frameworks for data exchange. Data pipelines connected to the channels might modify the received data contents and/or their structures to facilitate downstream consumption in general, and data integration in particular.
83. Schemas and information exchange models are fundamental for describing, and prescribing, how the data in-motion and at-rest is organized. Information exchange models enable the sharing and exchange of enterprise information that is consistent, accurate and accessible. These models are not intended to replace the disparate set of heterogeneous schemas used to persist information across the organization -- both data consumers and producers can continue to use their own schemas for data at-rest within their own environments.
Additional Notes
84. Data Management supports a variety of types of persistent stores, including the following: hierarchical, e.g. XML, folders; multidimensional, e.g. data cubes, star schemas; relational, e.g. SQL databases; and non-relational, e.g. column stores, key-value stores, spatial DBs, document stores, graph DBs, triple stores (RDF), etc. It also supports two main classes of processing styles[4]: ACID and BASE. ACID is a set of properties that characterize transactions in traditional, relational DBMSs: Atomicity, Consistency, Isolation and Durability. In contrast, BASE is a type of processing that relaxes some or all four ACID properties and has become the processing style in newer data environments. Accessing the data from persistent repositories can be done with a variety of standard protocols and languages, including SQL, ODBC, JDBC, Open Data Protocol (OData), ADO.NET, C, C++, REST, SOAP, XML, XPath and Java.
85. These exchange models can be easily used by data services integrated with an enterprise service bus or by Data-as-a-Service (DaaS) solutions. Such models can be based on the Data Documentation Initiative (DDI), the Statistical Data and Metadata Exchange (SDMX) model and other standards.
86. In the case of data coming from external sources, the reliability of the source and its stability in terms of time and format should be assessed. For data coming from private companies, additional actions need to be performed, e.g. to assess the reliability of the provider and its willingness to provide the data. In some cases, it can be necessary to act on the legislative level to secure data provision, which requires specific competences. In all cases, clear contracts need to be set up and managed in time with the providers, which will include various degrees of harmonization and/or structure agreements that can range from loose to strict.
87. Data can be made available in different ways, e.g. by moving it into a persistent environment (for example relational database, NoSQL, data lakes, big data storage, etc.), setting up a data pipeline for processing, or configuring other types of data flow execution jobs.
E. Information Sharing
Summary
88. The ability to make (statistical) information (i.e. data and metadata) available to authorized internal and external users and processes. This includes:
- Making data available via Catalogues and other API-based data publication mechanisms to allow consumers to find and browse data based on multiple criteria and methods
- Enabling the production of new insights via a combination of visual representations, traditional statistical modelling, machine learning and other advanced analytics methods
- Publishing data, with its pertinent metadata, via a range of internal and external channels
- Anonymizing data to ensure appropriate levels of confidentiality
Lower Level Capabilities
89. Specialisations of Information Sharing are:
- Data Sharing
- Metadata Sharing
90. The Lower Level Capabilities for the Data Sharing capability (inherited by both Data Sharing and Metadata Sharing) are:
- Disclosure Control
Obfuscate, anonymize and/or redact information deemed sensitive by security and privacy policies by applying data suppression, perturbation, summarization or other techniques to ensure the appropriate level of confidentiality while preserving the usefulness of the data outputs to the greatest extent possible. - Publication
Make information sets available, either immediately or at a specific future date and time, to authorized consumers, both internal and external, via a range of (output) Exchange Channels. - Search and Exploration
Provide support for authorized internal and external users and processes in finding, ranking and browsing information sets based on their affinity to a set of target concepts or keywords. - Visualization
Create and maintain visual representations of information in order to communicate its content clearly and efficiently.
Representations include table or cube structures, but also diagrams, maps, graphs, etc., including the use of colours. - Data Analysis Support
Enable authorized users to perform Data Analysis, i.e. inspecting data and producing statistical models with the purpose of finding new insights and validating assumptions about that data.

Figure 6: Information Sharing
Description
91. This capability is probably the most complex of all CSDA capabilities. This is because of the duality of functionality in this capability. Information Sharing has two sides to it: the “giving” and the “taking”.
92. “Giving” deals with making data and metadata available to a selected audience, by opening up selected information sources through an appropriate set of exchange channels. Most of the “giving” takes place in Publication, but in some cases Disclosure Control is involved in order to preserve the privacy of persons or companies in the population. But much of the work involved here is actually around setting up and configuring the connections through Information Logistics. This involves making decisions about the mode of operation (CONNECT vs COLLECT, as explained in chapter IX), and (in case of COLLECT) setting up the necessary persistence mechanisms and related policies, taking into account the type and anticipated usage of the information as explained in chapter VII. And lastly, “giving” also involves deciding about, setting up and configuring the necessary mechanisms (exchange channels) for allowing information consumers to find and access (“take”).
93. The “taking” has to do with the finding and accessing of information, previously made available through “giving”. The ones actually doing the “taking” are the consumers (human beings, processes, systems) of data and metadata, internally (as part of same other capability) or externally. And in fact, the lower level capabilities for the “taking” included in Information Sharing are actually abilities to support such activities of information consumers. “Taking” again involves exchange channels, set up previously in "giving".
94. Data and metadata need to be exposed to both internal and external consumers (processes, people, and applications) via publication (exchange) channels. Information published this way becomes available to authorized user for downstream consumption.
95. Published information needs to be findable and discoverable, and this capability provides the abilities to browse and search. The ranking of search results is essential so that the user can easily distinguish the most relevant information sets from the less relevant ones. Once the desired information sets are identified, the information provided in the search result should be enough to access the actual data and/or metadata.
96. Visualizing data and metadata in different ways and at different granularities is also critical. Visualization is viewed by many disciplines as a modern equivalent of visual communication. It involves the creation and study of the visual representation of data (and metadata), meaning "information that has been abstracted in some schematic form, including attributes or variables for the units of information"[2]. A primary goal of visualisation is to communicate information clearly and efficiently via statistical graphics, plots and information graphics.
97. This capability also provides the ability to support the analysis of data. This includes inspecting the data and applying statistical models with the goal of discovering useful information, suggesting conclusions, and supporting decision-making. Data analysis has multiple facets and approaches, encompassing diverse techniques, including statistical analysis, dashboarding, business intelligence, machine learning, and query languages.
98. When data assets are shared with consumers that don’t have full access to the underlying data points, some form of disclosure control is required. A wide variety of methods can be applied as part of this capability, including suppression, perturbation, summarization or other techniques to ensure the appropriate level of confidentiality and anonymity.
Additional Notes
99. Search and exploration is metadata-driven – access to the actual data is not required. Usually, a data catalogue capability provides the ability to browse and search. This catalogue may include a description of the used/needed authentication and authorisation to access the data assets and the selection and filtering options to retrieve the data. For exploring the data, a quality indicator is also invaluable.
100. Publication channels often rely on virtual or persistent data management solutions, e.g. data hubs, for consolidating and registering data to be published.
101. Once a data asset of interested is found in the catalogue, the actual data can be accessed using standard protocols, e.g. ODBC, JDBC, SOAP/Restful services, through APIs, or using standard query languages like SPARQL or GraphQL. For data exchange, a range of protocols can be supported, e.g. Open Data Protocol (OData), an open protocol that allows the creation and consumption of queryable and interoperable RESTful APIs in a simple and standard way. Standard exchange models could also be supported, including the Data Documentation Initiative (DDI) and the Statistical Data and Metadata Exchange (SDMX).
102. Public data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control.
F. Data Transformation
Summary
103. The ability to transform data to make them suitable for specific purposes downstream.
104. This includes:
- Checking data coherence against data descriptions coming from metadata system used in the organisation and flagging issues.
- Cleaning data by correcting input errors, deleting duplicates, imputing missing data, correcting data formats, and applying other data cleansing techniques.
- Harmonising data values using classifications coming from national and international standards.
- Coding data coming from textual or non-structured sources by using coded, enumerated value domains, e.g. classifications and code lists.
- Reducing the amount of data by filtering rows and selecting relevant columns for specific uses.
- Altering the data following security or statistical significance reasons.
Lower Level Capabilities
105. The Lower Level Capabilities for the Data Transformation capability are:
- Data Cleansing
Detect and correct data errors and inconsistencies in structure, representation and content, remove duplicates (after performing entity resolution), and fill in missing values with estimates. - Data and Variable Subsetting
Select from a dataset those records and variables that are relevant for specific purposes downstream, eliminating those that are not. - Variable and Unit Derivation
Create new statistical units and variables derived from those existing in a dataset. - Classification and Coding
Assign codes to textual descriptions according to pre-determined classification schemes. - Data Mapping
Establish correspondences between two data models for the purpose of delivery, access or persistence.
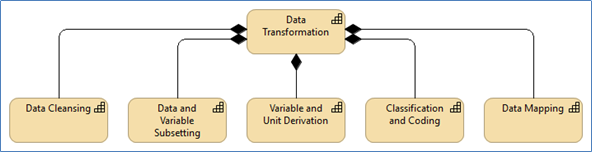
Figure 7: Data Transformation
Description
106. Data Transformation is the ability to transform data in a format that is (re-)usable for the Sharing capability. During the transformation process, the data can be cleansed, reformatted, harmonised, enriched, and validated. Data transformation allows the mapping of the data from its given format into the format expected by the consuming application. This includes value conversions or translation functions, as well as normalising numeric values to conform to minimum and maximum values.
107. Data transformation is not uniform for all statistical production: the same data can be transformed in multiple ways at different steps for multiple purposes and uses.
108. Data cleansing, or data cleaning, is the process of detecting and correcting (or removing) corrupt or inaccurate records or values from a data set. It refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. Data cleansing may be performed interactively with data preparation (data wrangling) tools, or as batch processing through scripting. The actual process of data cleansing may involve removing typographical errors or validating and correcting values against a known list of entities. The inconsistencies detected or removed may have been originally caused by user entry errors, by corruption in transmission or storage, or by different definitions and semantics used in different stores/sources. Data cleansing differs from data validation in that validation almost invariably means data is rejected from the system at entry and is performed at the time of entry, rather than on batches of data.
109. Reformatting is often needed to convert data to the same (standard) type. This often happens when talking about dates, time zones and other common data types.
110. After cleansing and reformatting, a data set should be consistent with other similar data sets in the system.
111. Data harmonisation is the process of minimising redundant or conflicting information across dimensions that may have evolved independently. The goal here is to find common dimensions, reduce complexity and help to unify definitions. For example, harmonisation of short codes (st, rd, etc.) to actual words (street, road, etc.). Standardisation of data is a means of changing a reference data set to a new standard, e.g., use of standard codes.
G. Data Integration
Summary
112. The ability to combine, link, relate and/or align different data sets in order to create an integrated information set.
113. This includes:
- Harmonizing variables and concepts across data sets and repositories.
- Standardizing data types across multiple platforms, technologies and solutions, including unstructured/semi-structured (NoSQL Databases) and structured (Relational Databases).
- Identifying multiple representations of the same entity across data sets and repositories.
- Aggregating, blending and creating mashups of heterogeneous sources (data sets, databases, data warehouses, Big Data, Linked Open Data) using a variety of techniques.
Lower Level Capabilities
114. The Lower Level Capabilities for the Data Integration capability are:
- Conceptual alignment
Map (or harmonize) concepts between multiple conceptual frameworks, taxonomies, ontologies and data/metadata exchange standards to support semantic integration. - Variable Reconciliation
Map (or harmonize) variables across datasets to improve comparability and linkage. - Format Standardization
Modify physical representations and data types to conform to standards and to best support readily shareable information. - Data Adjustment and Normalization
Perform seasonal and other statistical adjustments to data values to improve accuracy and align data values to a notionally common scale or a probability distribution to make datasets comparable. - Entity Resolution and Matching
Identify different instances or representations of the same entity (real-world object) across different datasets by inferring relationships and remediating conflicts to support data integration, record linkage and entity deduplication. - Data Aggregation and Enhancement
Clean, improve and extend information contents by joining records from multiple datasets and/or heterogeneous sources, with potentially different representations, to produce a more comprehensive view of an entity, concept or other subject of interest.
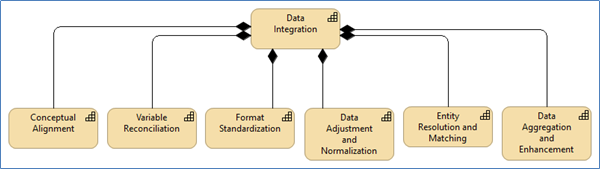
Figure 8: Data Integration
Description
115. Data integration is a key capability of the target architecture supporting the statistical organisation’s ability to fulfil information needs from multiple data sets. According to GAMSO, data integration is "the process of combining data from two or more sources."
116. At many points in statistical production data needs to be linked, integrated and consolidated from multiple sources. This requires harmonization at multiple levels, e.g. concepts, variables and formats, together with agile data modelling and structuring allowing users to specify data types and relationships as needed, especially in schema on-read scenarios.
117. The results of the integration could become new data sources that need to be persisted and managed independently in statistical registers, master data solutions, and other types of data hubs, e.g. data registries, data warehouses, etc. They could also include the generation of semantic models and ontologies.
118. A data integration technique commonly used in the statistical domain is record linkage, i.e. finding records that refers to the same entity across multiple data sources. Record linkage benefits from entity resolution and matching, since it requires to infer relationships and remediate data conflicts. It produces as a result and enhanced, more comprehensible view of a set of entities of interest.
H. Information Governance
Summary
119. The ability to manage information (assets) through the implementation of policies, processes and rules in accordance with the organization's strategic objectives.
120. This includes:
- Defining roles and responsibilities.
- Defining and assessing data quality indicators.
- Defining and enforcing rules for disclosure control.
- Setting and enforcing policies related to data and metadata lifecycle management, including schemas and data exchange models.
- Ensuring the organization can meet data-related regulatory compliance requirements.
Lower Level Capabilities
121. Specialisations are:
- Data Governance
- Metadata Governance
122. The lower level capabilities for the Information Governance capability (inherited by both Data Governance and Metadata Governance) are:
- Roles Management
Define information-related roles (e.g. steward, custodian, etc.) and maintain their allocations to people and organizational structures over time. - Quality Management
Assess information sets against relevant standards (format, semantics and level of quality), and define and monitor quality indicators. This includes:- Review and Validation
Examine information in order to identify potential problems, errors and discrepancies, in terms of validity (against business rules), accuracy (conformity to a standard or true value), completeness, and consistency (with other referential info) to ensure the appropriate level of quality.
- Review and Validation
- Sharing Management
Define and enforce rules for sharing information that is deemed sensitive by implementing security and privacy policies and manage how obfuscation, summarization, anonymization and other disclosure control techniques are applied. - Lifecycle Management
Manage the release and configuration of information changes, from creation/acquisition to persistence, enrichment, usage, sharing, archival and destruction. This includes the ability to define and implement retention rules for controlling the persistence (i.e. at-rest) of information. It also includes:- Schema Management
Maintain persistent schemas (e.g. relational, XML, etc.) for information at-rest. - Exchange Model Management
Maintain physical exchange models for information flows (in-motion), i.e. common vocabularies for interoperability,
- Schema Management
- Compliance Management
Manage (measure, enforce) the degree of compliance with governance policies regarding standardization, security, privacy and lifecycle management.

Figure 9: Information Governance
Description
123. GAMSO defines "Governance" as "Establishment of policies, mechanisms, and continuous monitoring required for proper implementation by an organization."
124. Gartner defines information governance as the specification of decision rights and an accountability framework to ensure appropriate behaviour in the valuation, creation, storage, use, archiving and deletion of information. It includes the processes, roles and policies, standards and metrics that ensure the effective and efficient use of information in enabling an organization to achieve its goals.
125. Information Governance is the ability to define, implement, monitor and enforce the execution of policies concerning all information the statistical organisation somehow has a responsibility for (e.g. as user, creator or provider). Within this capability, several layers can be distinguished. The top layer is where policies are defined. As explained before, it is recommended to do this by "type of data", i.e. sets of policies that apply to specific classes of data. The next layer is the implementation of these policies. This specifically includes being involved in the design and implementation of new or changed capabilities (GAMSO: Capability Development), as policies often have to be ingrained into the fabric of the organisation. Yet another layer is where the monitoring of compliance occurs, i.e. the actual behaviour of the organisation (in this context, specifically in the CSDA Core Capabilities) is measured against the norms set out in the policies. And lastly, there is the layer of correction, where deviations of the norms are rectified, and measures are taken to prevent re-occurrence. In fact, these layers correspond to the 4 steps in the Deming circle, PDCA (Plan, Do, Check, Act).
126. As explained before, the specific problem in this day and age is the fact that information is extremely dispersed, easily copied and moved through digital networks. We all are probably aware of the struggle creators of intellectual property such as music, songs, etc. have to control the (paid) use of their work. The task of a Statistical Organisation in managing and governing the information acquired or created for the execution of its mission is truly a daunting challenge.
127. In addition, the sheer volume of information that is available and the increasing appetite of NSI’s for tapping into the potential value of that enormous volume, leads to new types of problems as well.
I. Security & Information Assurance
Summary
128. The ability to maintain security and continuity of (the availability of) all data and metadata under control of the Organization.
129. This includes:
- Granting access to authenticated and authorised users and successfully deny access to all others
- Applying security to data in transit and at rest, to an appropriate level in line with the relevant official security classifications and Privacy Impact Assessments (if applicable)
- Ensuring the preservation of the integrity and availability of data.
- Ensuring the business continuity of the system, putting in place the capability to overcome temporary problems and ensuring the availability of alternative sites in the event of a disaster.
- Detecting hardware and software errors and bring the system back to a consistent state.
- Managing security rules, also in connection with external systems providing data (either administrative sources or Big Data).
- Monitoring user actions to identify security breaches.
- Providing intrusion detection and intrusion prevention to the hosted infrastructure
- Protecting user privacy.
- The use of data encryption techniques where applicable.
Lower Level Capabilities
130. The Lower Level Capabilities for the Security and Information Assurance capability are:
- Authentication
Define and implement procedures and mechanisms for secure identification of users. - Authorization
Define and implement procedures and mechanisms for access control to (statistical) information. - Security Administration
Add and change security policies and their implementations, manage security groups and access control to information assets. - Assurance and Asset Protection
Monitor security attributes to uphold the stated security policy, data usage, loss and unintended disclosures. - Availability
Maintain availability of data and metadata according to existing service level agreements and other contracts and policies despite abnormal or malicious events. This includes:- Information Backup (of which Data Backup and Metadata Backup are specializations)
Define information backup strategies, policies, procedures and responsibilities based on information requirements. - Replication and Synchronization
Maintain multiple copies of information contents to satisfy non-functional requirements while keeping them consistent by physically moving and reconciling them across disparate systems and models.
- Information Backup (of which Data Backup and Metadata Backup are specializations)
- Audit
Provide forensic information attesting that datasets have been created, read, updated or deleted in accordance to stated security policies. - Risk Management
Identify, evaluate, and prioritize risks, including cyber threats, provide mechanisms to monitor and minimize them, and train users on risk-related topics.
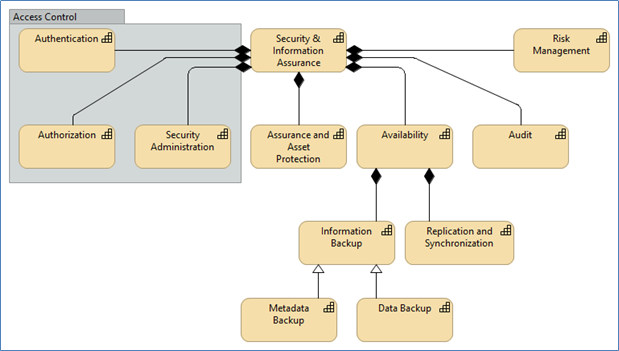
Figure 10: Security & Information Assurance
Description
131. The provision of Information Assurance and Security in an ever changing statistical data world has to be fluid. This is due to the changing IT landscape with an ever increasing drive to Big Data.
132. The fundamental ethos for Security and Information Assurance to protect the confidentiality, integrity and availability of data remains unchanged, regardless of the sources of the data.
133. It is important that the security of the statistical organisation engenders trust from the stakeholders, whether it be data suppliers (whose interest would be maintaining security of data which is probably confidential), or data consumers (who would be interested in the continued availability, integrity and quality of the data).
134. With increased access to an ever larger variety of data sources, and forging partnerships with other public and private organisations, security is essential. Working with big data is becoming ever more important to national and international statistical systems for fulfilling their mission in society.
135. In order to advance the potential of official statistics, statistical organisations will need to collaborate rather than compete with the private sector. At the same time, they must remain impartial and independent, and invest in communicating the wealth of available digital data to the benefit of stakeholders. We must consider the (now wider) range of data sources, which will include:
- Traditional (paper based) surveys
- On line surveys (in house hosted in cloud)
- On line surveys direct to businesses and individuals
- On line surveys hosted and run by 3rd Parties
- Data purchased from commercial organisations
- Web-scraped data, or other internet-based data sources
- Shared Government data
136. Each of these will have their own inherent security risks associated with them, and each must have the appropriate security controls applied to them. The use of a series of data zones with various levels of security controls can help to cater for the variety of requirements and needs of the different datasets.
137. A major objective of Information Assurance and Security is to facilitate access to Big Data sources as input into official statistics production. As these sources have their own potential security risks associated with them (e.g. unknown provenance, unknown virus status etc.), particular care needs to be taken to ensure the appropriate level of security controls are applied.
138. Where data is being shared with other organisations, there will be a need to provide assurance that the statistical agency will protect shared data to an acceptable level. This assurance can be facilitated by forming partnerships with the other organisation(s), whether they are public or private sector organisations, and setting up some form of service level agreements where the security controls to be applied to the datasets in question can be agreed.
139. Other data security risks can be realised when data from different sources is matched and linked, especially when applied to person information.
140. Additionally, data should undergo disclosure checking where there is a risk of revealing information about an individual or organisation, especially where, for example, it could lead to detriment to the individual or commercial damage to a business. This is particularly important for data that is being prepared for publication or dissemination.
141. There will be a need for data to undergo stringent checks when it is being brought into an organisation, regardless of its source and method of ingestion (e.g. streaming, batch, etc.). Multi-AV scanning should be adopted to reduce the risk of infection by viruses.
142. It is important that security and information assurance needs to be considered in the context of the data stored and used by the statistical organisation all through the statistical process, whether this process is executed on-premises or somewhere outside, in the cloud or even on systems owned and operated by other parties.
143. Because of the inter-operability aspects of such scenarios, It is strongly recommended that NSI's, in the implementation of their IA&S policies and mechanisms, apply the many international standards available. One in particular, in the area of access control, is the application of the PEP/PDP principle, i.e. the separation of Policy Enforcement from Policy Decision making, as defined by the architecture underlying the XACML standard.
J. Provenance & Lineage
Summary
144. The ability to capture and maintain provenance and lineage of data and metadata.
Lower Level Capabilities
145. The Lower Level Capabilities for the Provenance and Lineage capability are:
- Provenance Representation and Tracking
Keep track of the origins of information entities and the activities and agents that interact with them over time. - Lineage Representation and Tracking
Determine which CRUD (Create, Read, Update and Delete) operations are deemed relevant and trace how they affect the information contents and their causal relationships over time. - Workflow Provenance Traceability
Query and explore how information entities of interest flow thru activities and agents over time. - Data Lineage and Traceability
Query and explore data contents of interest that are causally related, trace their origins and how they are used and/or changed over time. - Metadata Lineage and Traceability
Query and explore schemas (and other metadata) that are causally related, trace their origins and how they are used and/or changed over time.

Figure 11: Provenance & Lineage
Description
146. Official Statistics will increasingly use data from different sources (both corporate and external). In order to be able to assess the quality of the data product built on these data, information on data's origin is required. The provenance and lineage data can be information on processes, methods and data sources that led to product as well as timeliness of data and annotation from curation experts.
147. Provenance is information about the source of the data and lineage is information on the changes that have occurred to the data over its life-cycle. Together they both provide the complete traceability of where data has resided and what actions have been performed on the data over the course of its life.
148. This capability entails the recording, maintenance and tracking of the sources of data, and any changes to that data throughout its life-cycle, in particular it should include date/timestamps, and who/what carried out the changes.
149. The World Wide Web Consortium (W3C)[3] provides an ontology to express provenance and lineage data.
K. Knowledge Management
Summary
150. The ability to manage intellectual capital (knowledge) in all its forms.
151. This includes:
- Capturing and formalizing knowledge in semantic models and actionable formats, like RDF, SKOS/XKOS, OWL, etc.
- Maintaining multiple versions of semantic models and knowledge representations at different levels of abstraction, and the lineage between them.
- Maintaining mappings between different models to support translations between vocabularies.
- Maintaining supporting artefacts, like architecture documents, best practices, guidelines, etc.
- Supporting inference and reasoning to derive new knowledge from existing one.
Lower Level Capabilities
152. The Lower Level Capabilities for the Knowledge Management capability are:
- Knowledge Lifecycle Management
Manage the release and configuration of semantic models and knowledge representations changes. - Concept Mapping and Matching
Find and maintain correspondences between concepts in different semantic models and knowledge representations for the purpose of delivery, access or persistence. - Inference and Reasoning
Derive new knowledge (implied facts) from explicitly represented, actionable knowledge (asserted facts). - Semantic Modelling
Capture and organize knowledge (concepts, terms, definitions) in domain-specific ontologies, classifications, taxonomies and thesauri to be used for communication purposes and/or to create actionable knowledge representations. - Knowledge Representations and Persistence
Formalize knowledge into actionable representations using standards, e.g. RDF, OWL, SKOS/XKOS, PROV-O, and keep that knowledge available over time. - Knowledge Sharing
Make knowledge available to authorized internal and external users and processes. - Knowledge Set Design
Create conceptual, logical and physical knowledge set designs, i.e. organized collections of statistical knowledge content.

Figure 12: Knowledge Management
Description
153. This is a capability to create, organize, augment, and share intellectual capital (knowledge) relevant to an organization or domain. It includes the creation and management of an environment to turn information into actionable knowledge, maintained in a physical or virtual repository, to benefit all aspects of the statistical production. Implementing this capability requires understanding the agency’s information flows and implementing knowledge acquisition and representation practices to make key aspects of its knowledge base explicit in a usable form.
154. (Davenport, 1994): “Knowledge Management is the process of capturing, distributing, and effectively using knowledge.”
155. Knowledge is ubiquitous: it resides not only in documents and databases, but also in experts’ minds and the agency’s routines, processes and practices. That’s why its capture and formalization is difficult but at the same time critical to the agency’s success.
156. Knowledge management deals not only with business knowledge but also with “support” knowledge that helps the organization to function, e.g. architecture documents, methodological approaches, data quality guidelines, security policies, etc.
157. Models are abstract description that hide certain details and emphasize others. A semantic model is an interconnected network of concepts linked by semantic relationships. The RDF graph data model is a semantic model consisting of a collection of triples of the form subject-predicate-object. Each triple can be viewed as an assertion about a relationship (the predicate) that holds between the subject and the object. RDF was developed by the W3C for the Semantic Web and provides a mechanism to make knowledge actionable and to derive (or infer) new knowledge from explicitly represented knowledge.
158. RDFS is a simple ontology language, or vocabulary, built on top of the RDF data model. An RDFS ontology also consists of a collection of triples, but this time subject and object are RDFS resources. In other words, the RDFS ontology is a collection of assertions between resources. In addition, properties in RDF are grouped into a class, which means they can also be extended.
159. A multitude of ontologies, classifications, taxonomies and thesauri exist to organize knowledge in RDF. Many of the commonalities among them are captured by the Simple Knowledge Organization System (SKOS), which is extended by the Extended Knowledge Organization System (XKOS) to cover the statistical classifications domain.
160. OWL is a knowledge representation language for building ontologies that represent complex domain models. OWL is more expressive than RDFS and has many advantages, including a clear separation between classes and individuals, a classification of properties (object, data and annotation), richer built-in datatypes and a variety of axioms to express logical statements about class relationships, property constraints (domain, range), etc. The latest version of the language is OWL 2.
161. In the context of statistical production, knowledge associated to data is organized into Knowledge Sets, an extension of GSIM Information Sets that consists of datasets, their referential metadata, other types of statistical content and actionable semantic descriptions, e.g. linked open data (LOD) and semantic web knowledge content.
Additional information
162. Knowledge is a fairly new topic in this context, and not yet well understood. For that reason it is kept separate in this version of CSDA. In future versions, knowledge may become more integrated, specifically with Metadata.
[1] Ref DAMA DMBOK
[2] Ref Wikipedia: https://en.wikipedia.org/wiki/Data_visualization
[3] https://www.w3.org/TR/prov-o/
[4] http://pubs.opengroup.org/architecture/togaf9-doc/arch/chap03.html